
Let’s look into some of the commonly used built-in standard shell variables
In this section we are going to see some of the standard shell built-in variables which we generally use in shell scripting.
# echo $? → this would show the exit status of the previous command run in shell (0 - success, anything other than 0 is considered as failure)
# echo $$ → this shows current shell ID (when run inside a script this would print the PID assigned to the shell).
# echo $@ OR # echo $* → this prints the arguments passed when called for execution.
# echo $# → this would show up total number of arguments passed.
# echo $! → this would report PID of previous background process.
# echo $_ → this would print last argument being used in the previous command in shell.
Practice Example 1:
--------------------------
To check this out, let's create a shell script as shown below and run it:

So, after running this script it would print output similar to the one below:

NOTE: As you could see I've used the escape character (\$) to nullify the "$" symbol inside echo statement which otherwise, gets executed. So, likewise depending on requirement we could escape special characters to print them as it is.
Likewise, there are a few environment variables which we commonly use inside shell scripting and some of them are:
# echo $USER → prints the currently active user.
# echo $HOME → prints the home directory path.
# echo $PATH → prints the PATH which is being used for any command execution.
# echo $PWD → prints the present working directory.
The following screenshot shows all the built-in shell variables available in my RHEL6.x virtual system:


Shell redirection and usage of “*” (wildcard)
This is one of the most required parts of learning shell scripting. In this section, we’d learn how to send output of one command as input to another, and other similar operations.
For re-direction we could use standard operator | (pipe), > (override), >> (append), likewise there is <, << input redirection that we could use in shell.
1) | (pipe) = this would send output of a command as input to another command.
2) >, >> = these operators are used when we wish to send data/output to a file or to somewhere else (to null device).
Practice Example 1:
--------------------------
Let’s create and add text into a file using redirection operators. As you all know, when you try to add some text into a file which doesn’t exists then it would get created and text gets added as shown in the below snap:

- In the above image, I’ve used “echo” to send a text message to file using “>” operator.
- The file “file1.txt” was not there, but got created when I used echo statement.
- To append some more text, I’ve used “>>” which gets added at the end of the file.
I'll write about “|” (pipe) operator along with “regular expression” section later in this page.
Practice Example 2:
--------------------------
Now, let’s see the usage of “*” (wildcard characters) and also about “?” (character operations). The "*" character denotes any combination/characters when used along with commands/regular expression.
I'll demonstrate this by using "ls" command (list files/directories) as shown below (within current working directory):
- To print all files with ".txt" extension ===> "ls *.txt"
- To print all files with the word "file" at the beginning ===> "ls file*"
- To print all files with the word "loop" in === "ls *loop*"

Practice Example 3:
--------------------------
The usage of “?” character would represent a single character and could be used as shown:
- To search only those files with name “file” and ending with a single digit number or character:
→ “ls file?”
- Likewise to list files with the word “file” and ends with two characters(alphanumeric):
→ “ls file??”

stdin, stdout & stderr
There is a standard input data stream abbreviated as “stdin” (<0), standard output stream abbreviated as “stdout” (1>) & standard error stream which is abbreviated as “stderr” (>2) which are very much essential in scripting part.
By default, the “stdin” data stream is from keyboard, “stdout” stream is to the console/terminal & “stderr” is also to console/terminal. We could redirect these data streams to something other than defaults. One simple usage of this is when we wish to store the output of a command to a file/variable, otherwise, when we wish to suppress/hide errors while processing some commands.
Practice Example 4:
--------------------------
So, let’s store output (stdout) of a command to a file using redirection operator:

In the above screen shot :
- The output of the command “uname -a” is redirected using “1>” operator to a file “/tmp/system.data”.
- By default “>” operator would store the output as directed to a file as shown.
- The output of “cat /etc/redhat-release” is redirected to the file “/tmp/system.data” using “>>” operator.
Now, let’s see how we can suppress standard error which gets printed on console otherwise. This is sometimes required in shell scripting where we wish to suppress/hide errors. Please refer the below screenshot for easy understanding:

- Initially the file “hello.txt” was not there.
- So, when I ran “cat hello.txt” it errors out.
- To suppress the errors I’ve used “2> /dev/null” to redirect errors to null instead of console/terminal.
- Likewise, to suppress both standard output & standard error, we could either use :
“> /dev/null 2>&1” OR “&> /dev/null” as shown in the above snap.
What is /dev/null?
The "/dev/null" device is a special file. It is typically used for disposing of unwanted output streams of a process, or as a convenient empty file for input streams. This is usually done by redirection.
Regular expression commands (regex)
There are a lot of built in shell commands which are most commonly used such as “grep”, “sed”, “awk”, “echo”, “tr”, “cut”, “head”, “tail” etc., to perform required operations.
A regular expression (also called a "regex" or "regexp") is a way of describing a text string or pattern so that a program can match the pattern against arbitrary text strings, providing an extremely powerful search capability.
Usage of grep
The grep (generalized regular expression processor) is a standard and most commonly used commands by any Linux or UNIX programmer's or administrator's. So, let’s discuss about this command usage along with examples.
Basic syntax: grep <option> <SearchPattern> <FromFile>
Let’s create a simple text file as shown to demonstrate the usage of “grep” command:

Practice Example 1:
--------------------------
Let's search for a pattern matching word from file "simple_file.txt" as demonstrated below:
- To search for all lines with the word "Hello" => grep "Hello" simple_file.txt
- To search for all lines with the word "hello" ignoring case => grep -i "hello" simple_file.txt
- To search for for all lines beginning with the word "Good" => grep "^Good" simple_file.txt
- To search for for all lines ending with the "?" => grep "?$" simple_file.txt
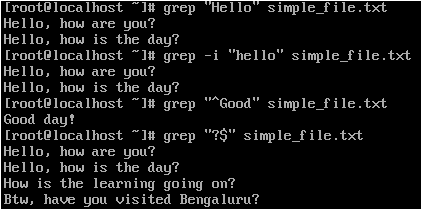
So, there are plenty of options available with “grep” command. Please check out the man page of the grep command “man grep” to find out other options.
Another usage of “grep” or “egrep” (as good as “grep -E” command) that I love to use in Linux is:
# egrep -v “^#|^$” <FileName>
This would remove blank and commented lines (lines begin with #) and print the rest. So, to shred out blank lines and comments from any config file and print actual configs we could use this. Say for example, you wish to print all config lines from "/etc/ssh/sshd_config" file by removing blank lines & comments, then we could run "#egrep -v “^#|^$” /etc/ssh/sshd_config"
Practice Example 2:
--------------------------
If there is a need to search for a matching string/word from multiple files or within all files under current directory then we could use “grep –r <Pattern/Word> <PathToSearch>” (-r denotes recursive). This would search in all the files in the path specified and prints out any matching pattern. Likewise, we could also use “grep –rin” parameters which could search recursively, ignore case sensitivity and also prints matching line-numbers as demonstrated here:

In the above snap the search pattern is "loop", so the grep command has searched in all files under current working directory (which is indicated by *) and lists out file name, line numbers and matching line of the search pattern.
Let’s talk about the powerful language “awk”
The “awk” command is installed by “gawk” package and it is a powerful pattern search and processing language. This was developed by “Aho, Weinberger & Kernighan” i.e awk. There is advanced version of “awk” called “gawk” also available. This tool is more useful when processing column-wise data or data separated with some characters.
Basic syntax of “awk”:
BEGIN { cmd; …cmd; } # Do before input
{ cmd; …cmd; } # Do on every line
….
/regex/ { cmd; …cmd; } # Do only on lines matching pattern
….
END { cmd; …cmd; } # Do after last input
One of the most useful option in “awk” is the “print” statement which can print fields such as $1 (first field), $2 (second field), $NF (last field), $((NF-1) (second from last). So, $0 would print complete line. Default field separator in "awk" is a white space (tabs/spaces) which can be changed using “-F” parameter.
So, let’s demonstrate usage of “awk” using examples.
Let’s say that you wish to print only the first field in the /etc/passwd file where the separator is “:”.
# awk -F: '{ print $1 }' /etc/passwd
Likewise, let’s print the first and last fields in /etc/passwd :
# awk -F: '{ print $1, $NF }' /etc/passwd
Practice Example 1:
--------------------------
So, let’s print a message before listing all username and their home directories in /etc/passwd file and print a message at the end using “awk”.
# awk –F: ‘BEGIN { print “List of users and their home directories.\n” } \
{ print “User : ”$1”, \t home directory :”$6 } \
END { print “\nThat is all.\n” }’ /etc/passwd

Output would be similar to the below snap:

Practice Example 2:
--------------------------
Let’s print out all lines which ends with question mark (?) from the file "simple_file.txt" using “awk” statement. The output should show a beginning message and ending message.

Likewise there are many ways we could use “awk”, for more details read the man page of awk (run the command "man awk" to get more help in Linux systems). Another most commonly used command in regular expression is "sed", please read the man page of "sed" to learn more about it.
NOTE: I've covered only the basics required in shell scripting, so, please read further and try practicing. Also, refer the man page of any command before using it to understand syntax and how to use, and to learn about options available.
All the best!
3 comments:
Good insights into most useful and practical usage of shell scripting.
Thanks Prasanna
Thank you for providing useful information and this is the best article blog for the students. learn Python programming training course.
Python Training in Hyderabad
Post a Comment