

Now-e-days we get to hear a lot about automation specifically Infrastructure Automation. Technology has already shifted gears from manual way of controlling IT infrastructure towards automatic methods. This is much needed for today's fast/rapid changing technology or infrastructure as demands from customer end does also took a sharp turn from way of investing/setting up infrastructure towards hosted infrastructure which we call it as "Cloud". A commonly used term which basically allows/facilitates converting physical infrastructure into a framework which is easy to scale up and flexible which provides a virtual platform where everything is defined as service i.e IaaS (Infrastructure As A Service), PaaS (Platform As A Service), SaaS (Software As A Service) (cloud models) on the broader look. There is a similar wing where activities of operation and development could be closely associated which we commonly call it as "DevOps". Yes, I'm talking about one such tool that is being used to automate tasks in infrastructure which is "Ansible". A simple, easy to use, easy to automate tasks i.e to write playbooks, easy to understand and it uses YAML (Yet Another Markup Language).
Ansible is :[-] an open-source utility.
[-] built on Python.
[-] agent-less.
[-] originally written by Michael DeHaan.
[-] easy to learn and understand.
[-] works by using modules (core & custom).
[-] uses YAML syntax for creating playbooks.
[-] playbooks are used to automate tasks.
[-] easy to install and configure.
[-] works on push mode (connects to remote hosts and pushes modules).
[-] is idempotent (playbooks work in idempotent mode, meaning if desired state is already achieved then running playbook again would not make any changes).
Ansible can automate most of the tasks in an IT infrastructure. It natively uses SSH protocol to communicate and push tasks on to remote system and fetch the results. However, it can't perform a bare metal installation and can't monitor configuration drift.
Ansible architecture
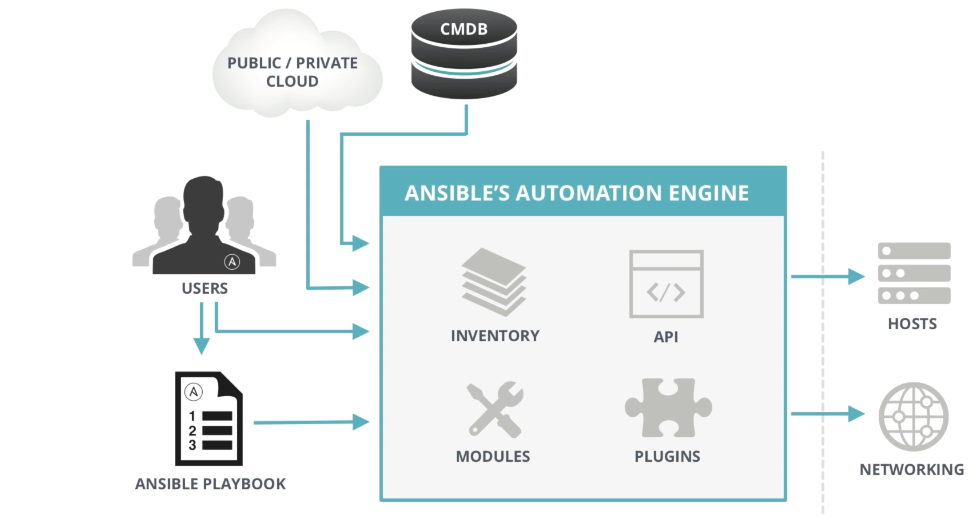 |
The architecture consists of a control node and one or more managed hosts. A control node is the one which got Ansible and related packages installed and configured. So, this control node would maintain an inventory which simply consists of hostnames or IP address of managed hosts and other configurations. Playbooks (tasks) are written in YAML syntax on control node to perform required tasks. These playbooks when run would execute tasks serially on targeted hosts. A control node should got Python 2.6/2.7 or Python 3 (version 3.5 and higher) installed and it could be either RHEL6/7.x system. A control node could be a Red Hat, Debian, CentOS, OS X, any of the BSDs, and so on (Windows is not supported as control node). On the other side all managed hosts should got Python 2.4 or later installed running with RHEL5/6/7. On older RHEL5.x python-simplejson package should also be installed.
By default, Ansible manages only Unix/Linux systems, however, starting from version 1.7 Ansible can also manage windows systems by using PowerShell instead of SSH for communication. Control node would use "winrm" module to talk to remote windows system.
By default, Ansible manages only Unix/Linux systems, however, starting from version 1.7 Ansible can also manage windows systems by using PowerShell instead of SSH for communication. Control node would use "winrm" module to talk to remote windows system.
Playbook: It is a file with .yml extension and consists of multiple plays. A play consists of set of tasks to be run on remote system. So, a playbook would normally contain targeted host (on which hosts the tasks needs to be run) and multiple plays. This is written in YAML syntax.
Inventory: It is a file which holds list of IP addresses or host-names of targeted systems. These names could be grouped.
Modules: These are either core (main) or custom modules which are written using Python and performs required functions. These modules would be pushed to managed hosts as per requirement when playbooks are executed.
Plugins: These connection plugins would allow Ansible control node to talk to managed hosts and by default it uses SSH. There are other connection plugins such as local, paramkio, winrm etc., are available.
How does Ansible works?
In simple terms, Ansible control node would establish connection (via SSH) with managed host and execute tasks defined within playbooks or as per roles set, and which in turn would push required modules (Python programs) to get the desired results. Those results would be retrieved and showed on the control node from where playbooks were executed.
ssh
Control Node <-----------------------------------------------> managed hosts
---->roles (playbook) -----> modules --->
At core there is "ansible.cfg" main configuration file, and there is an inventory file which holds a list of hosts to be managed, and finally there are playbooks (simple text files in YAML syntax) written to perform required tasks. At higher level there are roles which would make the structure easy and get the tasks done.
Let's install Ansible
How does Ansible works?
In simple terms, Ansible control node would establish connection (via SSH) with managed host and execute tasks defined within playbooks or as per roles set, and which in turn would push required modules (Python programs) to get the desired results. Those results would be retrieved and showed on the control node from where playbooks were executed.
ssh
Control Node <-----------------------------------------------> managed hosts
---->roles (playbook) -----> modules --->
At core there is "ansible.cfg" main configuration file, and there is an inventory file which holds a list of hosts to be managed, and finally there are playbooks (simple text files in YAML syntax) written to perform required tasks. At higher level there are roles which would make the structure easy and get the tasks done.
Let's install Ansible
Ansible package is available in EPEL (Extra Packages for Enterprise Linux) repo can be downloaded from here, otherwise using the ansible link https://releases.ansible.com/ansible
Easy way is to enable 'rhel-7-server-extras-rpms' repository and then run "yum install ansible" which would pull out all dependency packages which are mostly related with python and would install Ansible on the control node as shown here (installation done on RHEL7.1 system).
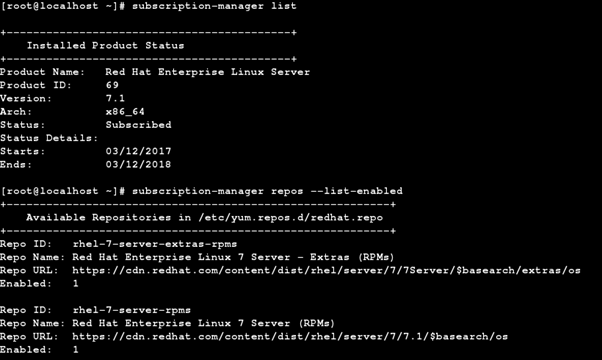
> By default 'rhel-7-server-extras-rpms' repo channel would not be enabled, so enable it by running "subscription-manager repos --enable rhel-7-server-extras-rpms" command.
> After this check out the enabled repos using the command "subscription-manager repos --list-enabled" as shown below:-
> Later, run the command "yum install ansible" which would pull up dependencies from both server and extras repo channel and install ansible. Below is the snap of dependent packages along with Ansible which would get installed:-
> The above snap is not clear enough to see what are all the dependent packages, hence, let me add another screen shot which shows this (considering RHEL7.x system is installed with core packages):-
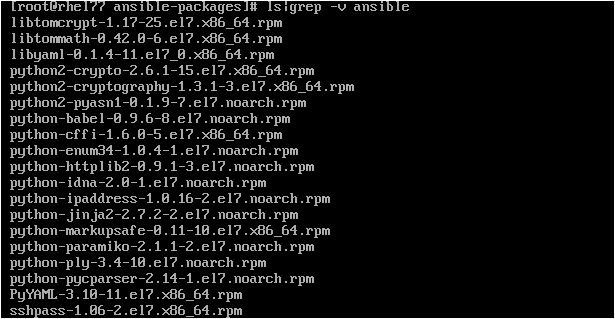
UPDATE:> Recently Red Hat has added a separate repository for Ansible and which can be enabled to get the Ansible packages installed. This change is from RHEL7.5 on-wards. So, to install Ansible on RHEL7.5 version or later, enable the required repository by running the below command (to get Ansible version 2.7) and then install ansible:
subscription-manager repos --enable rhel-7-server-ansible-2.7-rpms
subscription-manager repos --enable rhel-7-server-ansible-2.7-rpms
Let's Configure Control Node
After installing ansible on the control node, we need to setup key-based authentication so that the control node communicates with managed nodes using public-private keys which otherwise, requires entering password to connect. Once the public keys are exported to managed hosts, next step is to create a hosts list (list of managed hosts) and put them into a inventory file.
Let's create a simple setup with one managed host. By default all standard configuration and parameters are stored in "/etc/ansible/ansible.cfg" file. However, for this demonstration purpose, let's create a separate working directory "/ansible-projects", which holds the configuration file "ansible.cfg" and an inventory file named "inventory" which would store managed hosts details. In the 'inventory' file would hold managed hosts IP addresses or hostnames in one line each.
Once the 'ansible.cfg' and 'inventory' files got created, we could verify if that is correct. To understand which configuration file that ansible is going to use and ansible version one could run the below command :
"ansible --version"
To find out list of hosts being used as managed hosts for the current configuration, we could run the command "ansible all --list-hosts" as demonstrated below:
Once the 'ansible.cfg' and 'inventory' files got created, we could verify if that is correct. To understand which configuration file that ansible is going to use and ansible version one could run the below command :
"ansible --version"
To find out list of hosts being used as managed hosts for the current configuration, we could run the command "ansible all --list-hosts" as demonstrated below:
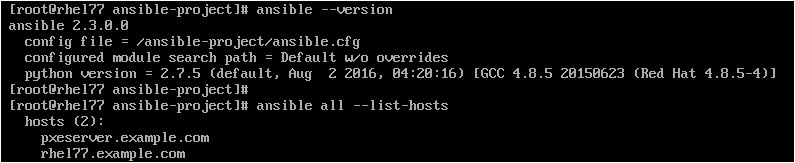
- In this setup,
control node is ----> rhel77.example.com
managed host is ---> pxeserver.example.com
parent directory : /ansible-project
configuration file : /ansible-project/ansible.cfg
inventory file : /ansible-project/inventory
> Let's run the "ping" command and check if connection can be established. The syntax to run standalone commands is as shown below :
"ansible <hosts> -i <inventory-file> -m <module-name> "
So, we could run the command "ansible all -m ping" (by default when no inventory file is specified ansible would consider the inventory file as configured in 'ansible.cfg' file in the current working directory).
"ansible <hosts> -i <inventory-file> -m <module-name> "
So, we could run the command "ansible all -m ping" (by default when no inventory file is specified ansible would consider the inventory file as configured in 'ansible.cfg' file in the current working directory).
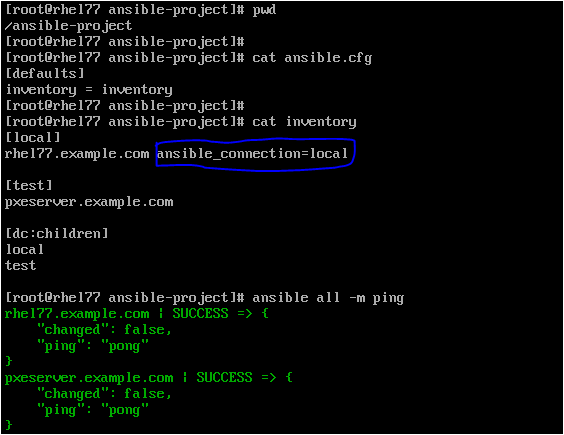
> You could see that the current working directory is "/ansible-project". The configuration file being used is "/ansible-project/ansible.cfg". The inventory host file is defined in the configuration file i.e "/ansible-project/inventory" as defaults, and the plugin "ansible_local" denotes that this is a local system and doesn't need to use SSH to connect. As we could see that the control node "rhel77" could successfully talk to "pxeserver" which is the managed host.
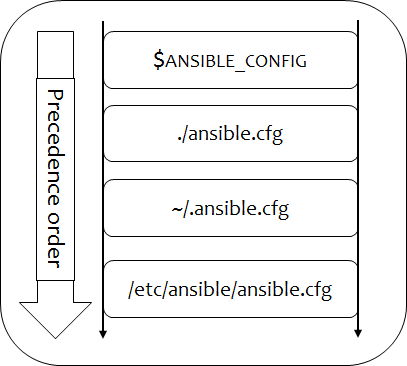 How & which ansible.cfg file to be used?
How & which ansible.cfg file to be used?
> Ansible follows a definite order to refer "ansible.cfg" configuration file when executing commands or running playbooks as shown in this picture.
So, if there is a "ANSIBLE_CONFIG" environment variable defined then it would take precedence over all and would be used. If not then "ansible.cfg" file defined in the current working directory if found, otherwise, ".ansible.cfg" file in the user's home directory. If there is no "ansible.cfg" file defined in the current working directory or if no ".ansible.cfg" file under user's home directory then it would refer to standard configuration file which is "/etc/ansible/ansible.cfg" file by default. So, to check which configuration file being used, one could run the command "ansible --version".
> Let's run some commands which is called "ad-hoc mode", where users can run any commands using either "command" module or "shell" module or any other module as shown below. The syntax for running an ad-hoc command is as shown below:
ansible <host-pattern> -m <module-name> [ -a 'module arguments'] [ -i inventory]
By default, the command module (this is pre-defined in "/etc/ansible/ansible.cfg" file as 'module_name') would be used when no module is specified. Like-wise, if you skip to mention the inventory file then Ansible would use a default one as per precedence order. Let's say to check the hostname, kernel version of the remote managed host, we could run this command:-
ansible <host-pattern> -m <module-name> [ -a 'module arguments'] [ -i inventory]
By default, the command module (this is pre-defined in "/etc/ansible/ansible.cfg" file as 'module_name') would be used when no module is specified. Like-wise, if you skip to mention the inventory file then Ansible would use a default one as per precedence order. Let's say to check the hostname, kernel version of the remote managed host, we could run this command:-
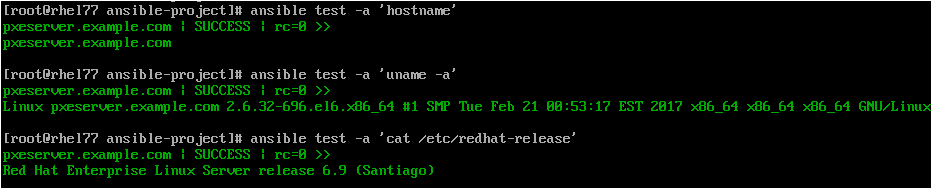
- The option '-a' would be used to pass arguments to the command module as shown above. As you noticed, I've not used "module-name" or "inventory file", so, Ansible would use "command" module as the default module and "inventory" file defined as per the "ansible.cfg" file under current working directory.
- To get a list of available modules, we can run the command "ansible-doc -l". To get help on a particular module, run the command "ansible-doc <module-name>". To get a series of commands or tasks to be run on managed hosts, we could use "playbooks".
- To get a list of available modules, we can run the command "ansible-doc -l". To get help on a particular module, run the command "ansible-doc <module-name>". To get a series of commands or tasks to be run on managed hosts, we could use "playbooks".
- A playbook is used to perform certain task using YAML syntax which is usually a text file with .yml extension. These playbooks would normally begin with "---" (three dash and this is optional) and would be run using the blow command :
"ansible-playbook <playbook-file.yml>"
These playbooks would contain one or more tasks to be executed and on one or more hosts. At broader level roles would be used. Using roles, we could define a structure which would separate variables, main tasks, files, etc., which is easier to maintain and understand.
- So, how does this helps? How could Ansible do infrastructure automation? Yes, once a system is installed in minimal mode (control node) that could be used by Ansible to run playbooks which would contain tasks for specific hosts. Tasks such as Creating Users, Setting Up Passwords, Installing Packages, Starting Services, Editing Configuration Files etc., could be coded as playbooks and run. The codes that are run using playbooks are not hosts specific, the same code/playbook could be used to run on other systems as well. Yes, we need to study how to create playbooks, roles, galaxy, using/declaring variables etc,. to work in Ansible. This is just an introduction, so, for further reading one could refer to http://docs.ansible.com/
"ansible-playbook <playbook-file.yml>"
These playbooks would contain one or more tasks to be executed and on one or more hosts. At broader level roles would be used. Using roles, we could define a structure which would separate variables, main tasks, files, etc., which is easier to maintain and understand.
- So, how does this helps? How could Ansible do infrastructure automation? Yes, once a system is installed in minimal mode (control node) that could be used by Ansible to run playbooks which would contain tasks for specific hosts. Tasks such as Creating Users, Setting Up Passwords, Installing Packages, Starting Services, Editing Configuration Files etc., could be coded as playbooks and run. The codes that are run using playbooks are not hosts specific, the same code/playbook could be used to run on other systems as well. Yes, we need to study how to create playbooks, roles, galaxy, using/declaring variables etc,. to work in Ansible. This is just an introduction, so, for further reading one could refer to http://docs.ansible.com/
11 comments:
This above information really Good beginners are looking for these type of blogs, Thanks for sharing article on Devops Online Training Hyderabad
Nice article, you may try this link also for more info.
Ansible Vault
Good post..Keep on sharing.. Kubernetes Training in Hyderabad
Nice post. useful for beginners Devops Online Course
Really wonderful visual appeal on this website, I'd rate it 10.
What's up, after reading this awesome piece of writing
i am also happy to share my experience here with colleagues.
It’s a awfully abundant advantageable to everybody..thanks for providing such varieties of valuable data
Offshore dedicated
I'm Unable to SSH.
[root@server1 ansible-project]# ansible all -m ping
192.168.146.133 | UNREACHABLE! => {
"changed": false,
"msg": "Failed to connect to the host via ssh: ssh: connect to host 192.168.146.133 port 22: Connection refused\r\n",
"unreachable": true
}
The authenticity of host '192.168.146.128 (192.168.146.128)' can't be established.
ECDSA key fingerprint is SHA256:bMdRPTu2s4FWB3rl4tW3l3A1ohpXQlWLOZJkiYF1W/o.
ECDSA key fingerprint is MD5:cf:7b:0f:d3:cd:ff:01:b0:78:fd:78:f9:58:47:60:7f.
Are you sure you want to continue connecting (yes/no)?
192.168.146.131 | UNREACHABLE! => {
"changed": false,
"msg": "Failed to connect to the host via ssh: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).\r\n",
"unreachable": true
}
Please send your query to SimplyLinuxFAQ@gmail.com
I feel very grateful that I read this. It is very helpful and very informative and I really learned a lot from it.
data science training in malaysia
Very Nice Blog…Thanks for sharing this information with us. Here am sharing some information about training institute.
tableau online training in hyderabad
Post a Comment